DeepSeek
Open-source LLM, генерация кода, мультимодальность. Языковая модель, чат-бот. API-решения для разработчиков.
Дата обновления:12.01.2026
0
Основной функционал
- DeepSeek — это экосистема ИИ-моделей и продуктов: веб-чат, мобильные приложения и API. В «фронте» — DeepSeek-V3.1/V3 как универсальные модели общего назначения, и «reasoning»-линейка DeepSeek-R1 для многошагового рассуждения. В веб-чате можно вести диалоги, подключать файлы и работать с длинным контекстом; то же доступно в приложениях и через API.
- Ключевая особенность актуального интерфейса — гибридный режим вывода: переключатель DeepThink позволяет мгновенно менять поведение между «Think» (развёрнутые рассуждения) и «Non-Think» (быстрые ответы). Этот же выпуск усилил навыки «агента»: инструментальный вызов функций, пошаговые задачи, более «цепкие» мультишаговые планы.
- Для разработчиков DeepSeek предлагает «кодовые» модели (DeepSeek-Coder / Coder-V2) с предобучением на репозиторно-уровневом корпусе и поддержкой инфиллинга/длинного окна — они закрывают генерацию кода, автодополнение и анализ проектной структуры.
- API-стек и релизы регулярно получают апдейты: например, свежая ветка V3-0324 объявлена с приростом reasoning-метрик, усиленным tool-use и открытыми весами под MIT-лицензией, что упрощает встраивание в свои пайплайны и on-prem эксплуатацию.
- Практически DeepSeek закрывает три класса задач: Ассистент-универсал (контент, поиск структуры в больших текстах, ответы по документам, быстрые брифы). Код и математика (объяснения, трансформации, автотесты, рефакторинг; у V3 сильные показатели на код/Math наборах, а R1 — на задачах рассуждения). Агентные сценарии (вызов инструментов, многошаговые пайплайны; в V3.1 это специально усилено).
- Важная грань экосистемы — открытость. Помимо публичного чата с бесплатным доступом к актуальной модели (V3.1), компания продвигает открытые отчёты/веса (V3, R1 и дистилляты), что снижает стоимость интеграции и даёт гибкость выбора: от «просто пользоваться через веб» до полного контроля в собственных окружениях.
- Отдельно стоит отметить reasoning-линейку R1: модель обучалась с упором на многошаговую правильность (RL-тренировка и дистилляция образцов рассуждения), что вывело её на уровень «соревнующихся» закрытых решений в задачах логики/кода/математики — при заметно более доступной схеме использования (открытые веса/лицензии).
Технические особенности
- Архитектура V3. Технически DeepSeek-V3 — крупная Mixture-of-Experts (MoE)-модель (671B суммарных параметров, ~37B активных на токен), построенная на двух ключевых идеях: Multi-head Latent Attention (MLA) и DeepSeekMoE. MLA снижает требования к памяти в инференсе за счёт низкоранговой компрессии K/V (уменьшение KV-кэша при генерации) и компрессии Q-активаций — без заметной потери качества относительно стандартного MHA. DeepSeekMoE реализует тонкую маршрутизацию экспертов и «aux-loss-free» балансировку нагрузки, минимизируя деградацию качества от самого факта балансировки; сверху добавлен multi-token prediction как обучающая цель.
- Инфраструктурные оптимизации: DualPipe/overlap вычислений и коммуникаций, экономия памяти (рекомпьют нормализаций, вынесение EMA на CPU), FP8-тренинг, оптимизация all-to-all между узлами и практические советы по железу. Все эти решения направлены на снижение латентности и стоимости как обучения, так и инференса на больших партиях/длинных окнах.
- Режимы V3.1. В пользовательском стекле V3.1 добавил гибридный инференс («Think/Non-Think») и усилил умения «агента» — от вызова инструментов до многошаговых задач. Это фактически позволяет выбирать между скоростью и глубиной на лету по сценарию.
- Reasoning-ветка R1. В DeepSeek-R1 основной вклад — обучение через подкрепление с мало-/без-SFT стадией и последующая дистилляция рассуждений в меньшие «плотные» модели (на базах Llama/Qwen), что даёт «разум по требованию» в компактном формате. Отчёт фиксирует конкурентность с OpenAI-o1 на задачах логики/кода/математики. Известные особенности ранних вариантов — «language mixing» и читаемость «цепочек мыслей» — частично нивелированы многостадийным пайплайном (cold-start + RL).
- Длинный контекст, KV-кэш и производительность. Практика инференса на современных GPU подчёркивает: при росте batch/контекста именно KV-кэш становится главным потребителем памяти; решения наподобие MLA напрямую адресуют это узкое место. Для продакшна это означает более стабильные задержки на длинных документах и возможность держать большие окна без экстремальной стоимости железа.
- Открытые релизы и лицензии. Ветка V3-0324 опубликована с открытыми весами под MIT-лицензией и улучшенным инструментальным поведением; это упрощает BYOM/BYOK-схемы и эксперименты on-prem.
- Безопасность/прозрачность. Исследователи отдельно обсуждают риски «чёрного ящика» в reasoning-моделях (включая R1): стремление к максимальной точности может снижать читаемость рассуждений для человека; фиксировались феномены смешения языков. Это накладывает требования к guardrails и мониторингу при рабочем внедрении.
Тарифы
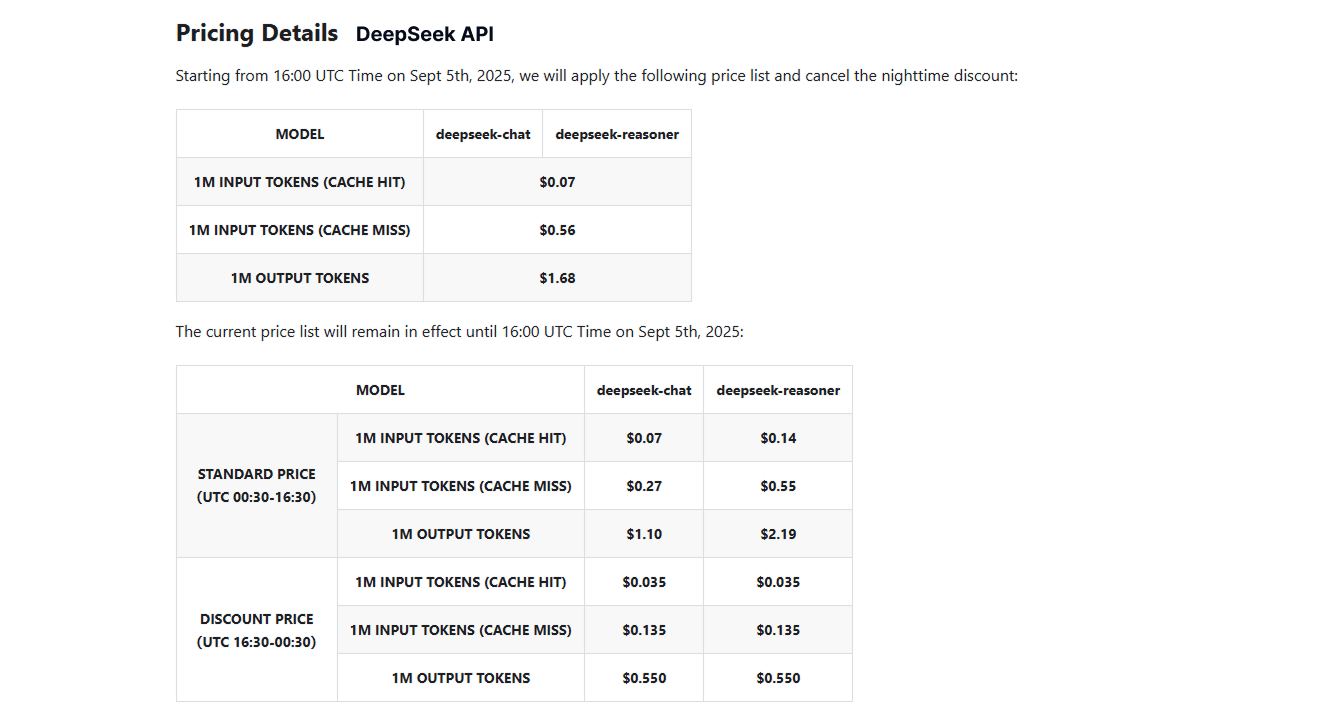
Кому подойдет
- Фаундерам и малым командам. Низкий порог входа: бесплатный веб-чат (V3.1) для задач письма/анализа и быстрые прототипы; при росте — переход к API/открытым весам.
- Инженерам/ML-практикам. Код-модели (Coder/V2), открытые веса V3/R1, MIT-лицензия релиза V3-0324 — удобно для встройки, RAG/агентов, on-prem.
- Data/аналитикам и техписателям. Диалоги по длинным документам, структурирование, брифы; переключение Think/Non-Think под задачу (быстро vs глубоко).
- Энтерпрайзам. Контроль затрат за счёт эффективного инференса (MLA/MoE), открытые отчёты и возможность собственной развертки/аудита; но требуются внутренние политики безопасности для reasoning-моделей.
Бесплатные кредиты
Бесплатна, но по API - платно